Psycho Papers 53 : Mes dernières publications
Influencer les comportements plus éthiquement - La négligence de la soustraction - L’asymétrie dans le blâme et l’éloge - Quel est le meilleur indicateur de la réplication ? - Comment savoir s’il fait chaud ?


Aujourd’hui, je vous propose une édition spéciale des psycho papers, dans laquelle je vous parle des dernières études que j’ai publiées, presque toutes en 2025. Ce n’est pas que je suis particulièrement productif cette année (je suis d’ailleurs particulièrement PAS productif, étant donné que je suis presque constamment malade à cause de l’enfant à la crèche), mais que la publication scientifique est complètement imprévisible : certains de ces articles ont été soumis il y a plus de 3 ans, quand d’autres ont été soumis en septembre dernier. Le fait qu’ils aient tous été acceptés en début d’année tient plus de la coïncidence qu’autre chose. Ensuite, vous allez pouvoir le constater, ces articles n’ont rien à voir avec les autres sur leur contenu. C’est un fait que j’aime beaucoup sur mon métier. J’ai développé des compétences techniques assez complexes, et on me propose des collaborations pour les utiliser sur des sujets très différents. ça me permet de toucher à plein de domaines différents et d’en apprendre beaucoup sur ces domaines. De ce fait, au niveau théorique, je ne suis expert en rien et ça me va très bien comme ça. Bonne lecture !
Influencer les comportements plus éthiquement
Il y a deux ans et demi, une équipe de la commission européenne, composée de Hendrik Bruns et Yavor Paunov, a contacté mon laboratoire pour une méta-analyse. Comme c’est mon sujet d’étude, ça a été à moi de faire l’analyse statistique. Ces chercheurs ont eu une commande de la commission européenne pour déterminer l’importance de la transparence dans l’efficacité des nudges.
Si vous voulez un aperçu des nudges, je vous invite à lire l’article publié dans mon blog “Nudge : un vrai coup de pouce ?” à retrouver ici.
Simplement, les nudges sont des modifications dans l’environnement qui amènent les personnes à faire des choix différents, sans les obliger à changer leurs choix, et pour faire des choix meilleurs pour leur santé, leur environnement etc. Pour l’expliquer, le mieux c’est de donner des exemples :
Quand on écrit le nombre de calories perdues sur des marches du métro, on augmente les chances que les personnes prennent les marches plutôt que l’escalator
Les passages piétons en 3D réduisent la vitesse des voitures
Les cendriers en mode “votez pour votre préférence” augmentent les chances que le mégot ne finisse pas par terre
Retirer le terme « végétarien » sur les menus de restaurant pour mettre « avec viande » sur les plats avec viande augmente les chances de prendre le plat végétarien
J’ai mis volontairement les exemples en Italique. En effet, si vous cliquez sur le lien de mon blog, vous verrez qu’il n’y a aujourd’hui pas de preuve d’efficacité des nudges, et qu’il y a surtout des preuves de pratiques problématiques de recherche de la part des unités de recherches sur les nudges. Et si vous voulez en savoir encore plus, j’ai une vidéo d’une heure et demie dessus (ça commence vers 1h05 pour les nudges).
Bref, un point important des nudges est que, selon les chercheurs qui croient à son efficacité, il faut que le nudge soit opaque pour fonctionner. Si la personne qui expérimente le nudge connait le nudge, alors elle ne va pas adopter le meilleur comportement pour elle. Mais est-ce vrai ?
C’est précisément ce que l’on a testé dans notre étude.
Nous avons trouvé 23 articles qui comparent un nudge transparent à un nudge non transparent. Nous avons appelé nudge transparent un nudge pour lesquel, on a expliqué au participant de l’étude soit comment il fonctionne, soit ce qui se passerait sans le nudge, soit la raison du nudge.
De plus, on a testé le type de nudge, l’effet du nudge (certains nudges réduisent un comportement, d’autres l’augmentent, d’autres veulent seulement changer les attitudes et pas le comportement etc.) et la qualité d’implémentation du nudge, à savoir est ce que le nudge a été testé sur un ordinateur en ligne, dans un laboratoire, ou en vrai dans la rue ou dans un vrai restaurant, etc.
Pour les résultats principaux, on a trouvé un effet faible de la transparence :
 Ici, on observe le diamant en bas que l’effet est positif, faible.
Ici, on observe le diamant en bas que l’effet est positif, faible.
Sauf qu’on observe également que cet effet est influencé par des pratiques de recherches questionnables
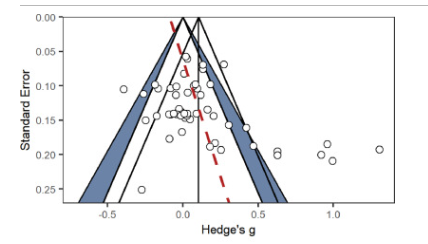
On a également remarqué que les études sont presque toutes faites en laboratoire sur un ordinateur (donc pas du tout en lien avec ce qui se passerait dans la vraie vie), que 88 % des effets portent sur le “nudge par défaut” qui est un seul type de nudge pas du tout représentatif de la diversité des nudges testés, et que presque aucune étude n’est préenregistrée.
Je ne vous ai présenté ici que les résultats des choix comportementaux, mais dans les études sur les attitudes, on a également trouvé des indices de p-hacking (de la triche pour rendre significatif des effets qui ne le sont pas).
Nos conclusions de cette étude sont importantes : Si les études ne sont pas biaisées, alors les effets transparents seraient plus forts que les effets non transparents. Si les études sont biaisées, alors les effets transparents ne seraient pas différents des effets non transparents. Dans tous les cas, l'hypothèse des chercheurs, que les nudges marcheraient mieux s’ils sont opaques, n’est pas soutenue par les observations. Les observations soutiennent plutôt l’effet inverse.
Nous avons donc présenté en discussion le fait que, pour que les nudges soient le plus démocratiques possible, ils doivent, par défaut, être transparents. En effet, si le gouvernement décide de modifier le choix de ses citoyens, il est toujours préférable d’expliquer les raisons de cette modification et les chercheurs, comme les gouvernements, ne peuvent pas se réfugier derrière l’argument du “si c’est opaque ça marche mieux” car cet argument ne tient vraisemblablement pas.
Le lien vers l'article :
Bruns, H., Fillon, A., Maniadis, Z., & Paunov, Y. (2025). Comparing transparent and covert nudges: A meta-analysis calling for more diversity in nudge transparency research. In Journal of Behavioral and Experimental Economics (Vol. 116, p. 102350). Elsevier BV. https://doi.org/10.1016/j.socec.2025.102350
La négligence de la soustraction
En 2021, Adams et ses collègues publient un article : The overlook of subtractive changes. Dans leur article, les auteurs indiquent que les humains, pour des raisons difficiles à comprendre pour l’instant, sous-estiment la soustraction.
J’en avais longuement parlé à Noël 2022, dans ce billet de newsletter : https://psychopapers.kessel.media/posts/pst_6602519836834e8ab3cd2ad3b8458bca. Si vous voulez un historique de pourquoi j’ai investigué cet effet, n’hésitez pas à le lire.
En somme, on a demandé à des participants français (une des nouveautés par rapport à l’étude originale) de modifier un parcours de golf qui ressemble à ça :

Dans un cas, on leur a demandé de le détruire, dans un autre cas de l’améliorer. Dans un cas ou leur demandé juste ça, et dans un autre cas, on rajoutait un énorme encart en rouge:
“N’OUBLIEZ PAS QUE VOUS POUVEZ AJOUTER OU RETIRER DES ÉLÉMENTS
AU PARCOURS DE GOLF”.
Nous avions fait ça pour répliquer à l’identique le travail des chercheurs de 2021. Nous résultats étaient presque identiques aux leurs, à savoir qu’on observe dans les idées rapportées qu’elles sont beaucoup plus des idées d’ajout (mettre une seconde mare, rajouter des bandes de sable, rajouter des coins, etc.) que d’idées de soustraction (enlever la bande de sable, enlever la barre rouge, etc.) mais aussi que les idées de soustractions sont légèrement plus rapportées quand on leur donne le gros indice rouge que quand on ne le donne pas. Plus important encore, ces idées sont indiquées parmi les premières, ce qui peut être expliqué par le fait que c’est difficile de générer des idées de soustraction, donc on se force au début et ensuite on n’y arrive plus.
Depuis cette newsletter, nous avions eu des retours des reviewers et de l’éditeur qui étaient très intéressants. En effet, en 2021, une autre équipe de chercheurs (Fischer et al. 2021) a écrit une critique de la première recherche qui s’applique aussi à la nôtre. Ils expliquent que le gros encart rouge pose un problème : on explique aux participants qu’ils peuvent AJOUTER OU RETIRER des éléments. Pas qu’ils peuvent retirer ou ajouter. Pourquoi ? Selon ces auteurs, cela montre aussi le biais des chercheurs qu’il est plus naturel pour eux d’indiquer ajouter puis retirer que retirer puis ajouter. Ils formulent également d’autres problèmes de l’étude initiale, mais qui ne s’appliquent pas à la nôtre.
Suite à cette critique, on a décidé de faire une seconde étude, cette fois en ne prenant que le cas d’amélioration du parcours, mais en modifiant l’encart rouge. Dans un cas, l’encart disait :
“N’OUBLIEZ PAS QUE VOUS POUVEZ RETIRER OU AJOUTER DES ÉLÉMENTS
AU PARCOURS DE GOLF”.
Dans un second cas, l’encart disait :
“N’OUBLIEZ PAS QUE VOUS POUVEZ RETIRER DES ÉLÉMENTS DU PARCOURS DE GOLF”.
Cela nous permettait de comparer les quatre conditions : sans encart, avec un encart ajouter/retirer, un encart retirer/ajouter et un encart retirer seul.
De manière assez surprenante, le cas amélioration - sans encart rapportait le plus d’idées de soustraction, suivi (et c’est normal cette fois) du cas encart retirer/ajouter.
En somme, on a trouvé que chez des participants français, dans un cas de brainstorming classique, on est aussi biaisé par la négligence des idées soustractives.
Une question se pose par rapport à cette négligence - est ce qu’on ne réfléchit pas aux idées soustractives ? Ou - est ce qu’on y réfléchit et on choisit de ne pas les rapporter ? Dans le premier cas, on serait face à un biais cognitif, tandis que dans le second cas, on serait face à un choix lié au contexte social. De notre coté, on a essayé de tester l’aspect social en regardant si les idées étaient rapportées différemment selon la norme (les idées préférées des golfeurs ou les idées généralement créées par les golfeurs) mais cela n’a rien donné. Selon Adams et al. (2021), cette négligence serait un effet cognitif. Selon Fischer, les études faites (dont la nôtre) ne permettent pas de correctement répondre à cette question.
Enfin, de notre côté, on est assez sceptique sur la tâche (pourquoi vouloir détruire un parcours de golf ?) mais aussi sur le fait que beaucoup des participants connaissent mal le golf en tant que sport . Ensuite, nous n’avons pas mesuré la qualité des idées générées, et les participants ont pu générer beaucoup d’idées d’amélioration, mais de faible qualité (des idées ni intéressantes, ni originales, ni pratiques). Il reste beaucoup à découvrir sur ce biais de négligence et j’ai hâte de voir ce qu’il va sortir les prochaines années.
Pour l’instant, il semblerait que, à la question “comment pourrait-on améliorer ceci”, nous comprenions “qu’est ce qu’il faudrait ajouter à ceci”.
Le DOI de l’article ne fonctionne pas encore (l’article a été définitivement publié ce matin), mais l’article est visible ici : https://onlinelibrary.wiley.com/doi/full/10.1002/jocb.1535
L’asymétrie dans le blâme et l’éloge
Dans cet article dont la récolte des données date de 2016 (oui, l’article a mis beaucoup de temps à être écrit puis à être soumis), nous nous sommes intéressés à la question suivante : attribue-t-on autant de blâme que d’éloge pour les choses que les gens n’ont pas volontairement fait ? ( Oui c’est tordu, c’est ça la philosophie).
Le scénario de nuisance est le suivant :
Nous souhaitons pour parler d’une entreprise. Le vice-président de cette entreprise est allé voir le président du conseil d'administration et lui a dit : « Nous envisageons de lancer un nouveau programme. Il nous permettra d'augmenter nos bénéfices, mais il nuira également à l'environnement ». Le président du conseil d'administration a répondu : « Je ne me soucie pas du tout de nuire à l'environnement. Je veux juste faire le plus de profits possible. Démarrons ce nouveau programme. » Ils ont lancé le nouveau programme. Bien sûr, l'environnement a été endommagé.
Le scénario de protection est le suivant :
Nous souhaitons pour parler d’une entreprise. Le vice-président de cette entreprise est allé voir le président du conseil d'administration et lui a dit : « Nous envisageons de lancer un nouveau programme. Il nous permettra d'augmenter nos bénéfices et de protéger l'environnement ». Le président du conseil d'administration a répondu : « Je ne me soucie pas du tout d'aider l'environnement. Je veux juste faire le plus de profits possible. Lançons le nouveau programme ». Ils ont lancé le nouveau programme. Bien sûr, l'environnement a été préservé.
Dans les deux cas, l’entreprise veut juste faire des bénéfices, et s’en fiche de l’environnement. Sauf que dans le premier cas, l’environnement est endommagé et dans le second cas, il est protégé. La question est donc - à quel point va-t-on blâmer la première entreprise des dommages causés et faire l’éloge de la seconde entreprise de la protection de l’environnement ?
Si nous n’avions pas un avis biaisé, nous devrions autant blâmer que faire l’éloge, car dans les deux cas, la raison n’est pas intentionnelle. Sauf que ce n’est pas ce qui est observé. En fait on blâme beaucoup plus que l’on fait l’éloge d’une conséquence involontaire d’une action. Cet effet a été découvert en 2004 par Joshua Knobe, qu’il a appelé l’effet de l’effet secondaire (side effect effect).
Et nous, comme on veut toujours compliquer les choses, on s’est dit, peut-être qu’on blâme plus parce qu’on attribue plus de libre arbitre quand les effets sont négatifs que positifs. C’est assez logique car il existe une théorie appelée “bad is stronger than good” qui dit que les expériences négatives ont un impact psychologique plus fort que les expériences positives. C’est pour ça que les divorces sont plus douloureux que les mariages sont heureux ; qu’on se souvient davantage des problèmes durant les vacances que les splendides paysages qu’on a vus, ou que se faire escroquer 50 € nous rend beaucoup plus en colère que de se voir offrir 50 € nous procure du plaisir.
Et pour encore plus compliquer le bousin, on a non seulement mesuré la croyance au libre arbitre, mais on a aussi essayé de la manipuler, c'est-à-dire de faire croire aux participants que le vice-président n’a pas de libre arbitre quand il choisit d’augmenter ses bénéfices. Bon, ça n’a pas bien marché.
Pour nos résultats, tout d’abord au niveau des corrélations, on a trouvé une corrélation très forte entre le blâme et la croyance au libre arbitre, plus forte qu’avec l’éloge, mais aussi et surtout qu’avec l’intentionnalité et la connaissance des risques. C'est-à-dire qu’on blâme les personnes plus parce qu’on les croit libres de faire les choix que parce qu’elles ont l’intention de faire ce choix.
 Peu importe l’univers, le blâme (en gris) était plus fortement attribué que l’éloge (en jaune). L’effet était bien plus fort dans l’univers indéterministe ou contrôle que dans l’univers déterministe.
Peu importe l’univers, le blâme (en gris) était plus fortement attribué que l’éloge (en jaune). L’effet était bien plus fort dans l’univers indéterministe ou contrôle que dans l’univers déterministe.
Et, en comparant le lien entre blâme, éloge et libre arbitre, On a trouvé que le blâme est largement plus lié à la croyance au libre arbitre que l’éloge. Autrement dit, on a non seulement trouvé que le mal est plus fort que le bien, mais que le mal est plus libre que le bien. Et ça, c’est une belle nouveauté.
Fillon, A., Chandrashekar, S. P., & Feldman, G. (2025). Asymmetries in Attributions of Blame and Praise, Intent, and Causality: Free Will, Responsibility, and the Side-effect Effect. In Collabra: Psychology (Vol. 11, Issue 1). University of California Press. https://doi.org/10.1525/collabra.128423
Quel est le meilleur indicateur de la réplication ?
En 2024, Isager et ses collègues proposent un nouvel indicateur pour décider de la valeur d’une réplication. Ce qu’ils disent est très simple : plus un article a peu de participants, mais beaucoup de citations d’autres chercheurs, plus il y a un besoin de le répliquer. En effet, un article fortement cité est un article qui a attiré l’attention, mais d’un autre côté, un article qui a peu de participants est un article dont l’effet est très imprécis, et dans le cas de la science actuelle qui n’est pas du tout rigoureuse, peut aussi induire des faux-positifs. Et on veut éviter de trop citer un faux-positif.
Le journal dans lequel l’article a été accepté, meta-psychology, a proposé de faire un commentaire de cet article. Avec Prasad Chandrashekar (qui est co-auteur de l’article au-dessus sur le blâme/éloge), on a fait un commentaire qui a été accepté. Voici ce qu’on en dit.
En premier, cet indicateur de valeur de réplication suppose que le nombre de citations d’un article est une mesure valide. Dans un monde normal, ça devrait être facile de savoir exactement combien d’articles sont cités par combien d’autres articles. Mais dans le monde scientifique actuel, ce n’est pas du tout le cas.
Premièrement, il existe des preuves que les articles les plus importants, ceux publiés dans les revues les plus prestigieuses comme Science ou Nature, le sont principalement par hasard. Ils sont donc plus cités, mais pas parce qu’ils sont plus important, seulement parce qu’ils ont plus de chance. Deuxièmement, des éditeurs scientifiques imposent des taux d’autocitations plus importants que d’autres. c’est le cas de MDPI par exemple. Dans les journaux MDPI, les auteurs citent beaucoup plus d’articles publiés dans MDPI que dans les autres journaux, ce qui augmente artificiellement le taux de citation. C’est une pratique anormale de la part de l’éditeur (on pourrait même parler de triche ?) mais si personne ne s’en inquiète, ils ont bien raison de profiter du système.
Troisièmement, il existe des services de boosting, c’est à dire des moyens de payer pour que des articles qui n’ont rien à voir avec votre travail vous cite quand même. Il y a aussi des auteurs prestigieux qui font payer des auteurs, souvent de pays pauvres, pour avoir leur nom sur l’article. Enfin, il existe des cas de référencement caché : les études pour lesquelles des citations n’apparaissent pas dans l’article, mais apparaissent dans les métadonnées transmises aux organismes de référencement. Ce sont des éditeurs frauduleux qui rajoutent des références à leur travail quand ils publient les articles. Et les organismes de référencement, de leur côté, refusent de prendre toute responsabilité à ce sujet.
Prasad et moi font donc la conclusion que le taux de citation d’un article n’est pas du tout un indicateur fiable, et doit être vérifié manuellement, et notamment la qualité des citations.
En plus de ces arguments, plutôt techniques, il existe des arguments philosophiques au problème de citation : ce n’est pas parce que la citation indique que les chercheurs sont intéressés par cet article, que cet article est intéressant en tant que tel. L’article peut, par exemple, ne pas du tout être intéressant pour le grand public. Deuxièmement, les articles cités l’étant principalement à cause du prestige du journal dans lequel il est publié, il peut mener vers de l’élitisme : on ne va répliquer que des études qui sont déjà mises en avant par leur journal. Cela va à l’encontre des principes d’open science comme par exemple le principe de diversité des chercheurs.
En parlant de philosophie, notre seconde série de critiques concerne le problème inhérent à la réplication. Sans vouloir être trop technique à nouveau, il existe des vrais et des faux effets. Il existe des effets forts et des effets faibles. Il existe des effets intéressants et des effets peu intéressants. Il existe des effets nouveaux et des effets connus. Il existe des effets consistants et des effets inconsistants. Toutes ces dimensions ne sont pas prises en compte dans l’algorithme proposé par Isager et ses collègues.
Plus important, plus une hypothèse est sévère, plus elle est importante pour faire progresser la science. Une hypothèse sévère est une hypothèse qui tente au maximum de prouver qu’une théorie est fausse. Ici encore, l’algorithme ne prend pas en compte la sévérité de l’hypothèse.
Une autre question se pose. Imaginons que nous décidions de répliquer un article, et que le résultat soit négatif : l’effet n’est pas répliqué. Que faire ? Nous ne pouvons pas réfuter l’effet parce que un effet a été significatif, l’effet original, et un effet non significatif, l’effet de la réplication. 1 partout, balle au centre.Il est possible qu’une seconde réplication soit-elle positive et dans ce cas on aurait 2 effets positifs et 1 non-significatif. Faut il donc la répliquer une deuxième fois ? mais alors combien de fois la répliquer ? Chaque réplication a un coût plus important que la précédente, et rien n’est dit sur le nombre de réplications à faire.
Enfin, cet indicateur ne dit rien de la théorie testée, que cela soit sur la relation de causalité entre les variables (et lesquels doivent-être répliqués pour que l’effet existe toujours) ou la relation à la pratique (quels effets doivent être retrouvés pour être utile à la pratique).,
Bref. Pour Prasad et moi, la réplication est extrêmement importante, mais l’idée que la réplication doit être privilégiée selon l’impact scientifique nous parait bancale, alors que ce qui compte, c’est d’améliorer la théorie scientifique.
Si vous voulez lire l’article, il est disponible ici : Fillon, A. A., & Chandrashekar, S. (2025, February 20). The Replication Dilemma: Potential Challenges in Measuring Replication Value—A Commentary on Isager, Van’t Veer, & Lakens (2024). https://doi.org/10.31234/osf.io/69b2g_v2
Comment savoir s’il fait chaud ?
Derrière ce titre curieux se cache un vrai article, une revue systémique du lien entre indice thermal et santé mentale.
Avec une équipe de chercheurs, on a codé 310 articles (j’en pleure encore) en fonction de l’indice thermal et les indicateurs de santé associés.
Les indices thermiques sont des manières de mesurer la chaleur ou le froid à un endroit. Certains d’entre eux prennent en compte le rayonnement du soleil, d’autres la pression atmosphérique, certains mesurent la température dans l’atmosphère, d’autres au sol. Certains mesurent la température dans des stations atmosphériques, d’autres dans les aéroports. Bon, il y a vraiment plein de variations à ce niveau-là.
De même, pour les mesures de santé, à peu près tout a été mesuré. Généralement, les chercheurs mesurent la mortalité toutes causes confondues, les problèmes cardiovasculaires, les problèmes digestifs et les maux de tête liés à la déshydratation. Mais ils ont mesuré un peu tout et n’importe quoi, et en particulier le risque d’avoir des enfants prématurés, mais également des problèmes respiratoires. De plus, dans la majorité des cas, les chercheurs ont mesuré le lien pendant des crises - des vagues de chaleur et parfois des vagues de froid. Les chercheurs ont plus rarement mesuré un lien pendant des températures moyennes et quand ils l’ont fait, les résultats sont largement moins importants.
Pour ce qui est des résultats, le PET est l’indicateur le plus utilisé, et de loin. Le PET est l’indicateur physiologique, qui est en gros la température de l’air à l’intérieur (sans prise en compte du vent ni du soleil). Le deuxième indicateur utilisé, mais qui l’est quand même moins est le Wet Bulb, qui se mesure selon la quantité d’eau qui s’évaporerait jusqu'à saturation de l’air.
Pour le lien entre température et indice thermique, visiblement, les vagues de chaleur sont plus dangereuses (et plus) que les vagues de froid. Et comme toujours, il n’y a pas de standardisation des pratiques des chercheurs, ce qui rend plus difficile la compréhension des risques, mais aussi des choix des meilleurs indices pour prédire les risques liés à la température.
Comme l’article a été fait par une autre équipe de recherche, exceptionnellement, l’article n’est pas en libre accès (tous les articles pour lesquels je suis auteur principal sont en libre accès).
Pantavou, K., Fillon, A., Li, L., Maniadis, Z., & Nikolopoulos, G. (2024). Thermal indices for evaluating the impact of thermal conditions on human health: a systematic review. In European Journal of Public Health (Vol. 34, Issue Supplement_3). Oxford University Press (OUP). https://doi.org/10.1093/eurpub/ckae144.1400
Voilà pour les articles du début d’années :) A dans deux semaines pour le retour des Psycho Papers normaux.
Psycho Papers
Psycho Papers