Psycho Papers #51 - On se méfie des algorithmes
Un raté de l’algorithme dans la protection de l’enfance - La meilleure étude à ce jour sur l’E-sport - ChatGPT n’est pas détecté dans les tests universitaires - Les raisons du dopage - J’ai mal à ma ruche. Abonnés : le lien entre trouble de la pensée formelle et schizophrénie


Avant de nous lancer dans la newsletter, sachez que je n’ai pas chômé les deux dernières semaines.
En premier, j’ai enregistré un épisode de Répare ta Science sur l’hypothèse infalsifiable de la dyslexie : https://creators.spotify.com/pod/show/adrien-fillon/episodes/La-meilleure-thorie-de-la-dyslexie-serait-elle-infalsifiable---RTS-9-e2u7ms6
Et si vous l’avez loupé, il y a toujours l’épisode sur le débat : “Peut-on investiguer des effets qui nous impactent personnellement ?”
Sur Youtube, j’ai publié deux vidéos parlant d’erreurs dans des études scientifiques : la première sur l’utilisation de l’Ocytocine dans l’autisme, la seconde sur une méta-analyse de l’effet de la luminothérapie sur la dépression.
Enfin, j’ai sorti une vidéo sur une étude permettant de prouver si l’astrologie fonctionne ou non. À retrouver ici !
Un raté de l’algorithme dans la protection de l’enfance
Ces dernières années, les services danois de protection de l'enfance ont subi une pression croissante, ce qui a conduit à l'adoption d'un algorithme d'aide à la décision. Cet algorithme a pour objectif d’aider les travailleurs sociaux à identifier les enfants présentant un risque accru de maltraitance.
Grâce à une demande d'accès à l'information, des chercheurs danois ont pu accéder partiellement à l'algorithme et effectuer un audit. Ils ont constaté que l'algorithme ne fonctionne pas correctement, générant des scores de risques incohérents et présentant une discrimination basée sur l’âge de l’enfant.
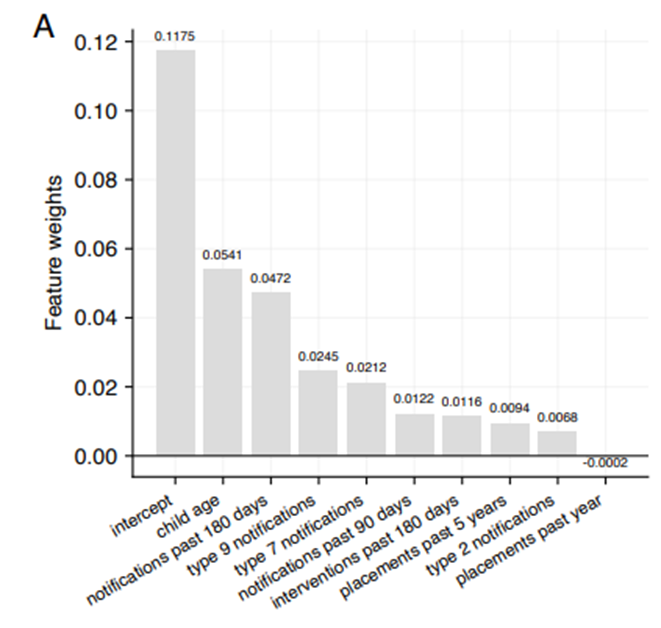
Dans la figure, on observe que l’âge de l’enfant est le facteur ayant le plus de poids dans l’algorithme, alors que son importance devrait être presque nulle. À l’inverse, le fait que l’enfant ait déjà été placé n’a aucun impact sur l’algorithme, alors qu’il devrait en avoir beaucoup plus.
Les chercheurs indiquent déconseiller fortement l’utilisation de cet algorithme dans la protection de l’enfance, et appellent à une évaluation rigoureuse de ces outils avant leur mise en œuvre et à un suivi continu après leur déploiement.
https://dl.acm.org/doi/pdf/10.1145/3630106.3658906
Notez que si cet algorithme n’a pas été déployé au Danemark, il est déjà déployé et utilisé en Pennsylvanie, où il discrimine largement les communautés noires, les pauvres, et les enfants présentant un handicap.
La meilleure étude à ce jour sur l’E-sport
L’E-sport, où sport électronique, est un ensemble d’organisations sportives qui se développent sur des jeux vidéo. Cette étude s’intéresse à la possibilité de travailler sur l’état d’esprit des sportifs pour mitiger les effets du stress avant leur partie. Les chercheurs ont travaillé avec 300 e-sportifs jouant à Counter-Strike, la moitié vivant une intervention de changement d’état d’esprit, l’autre moitié étant un groupe contrôle.
L’étude était un Registered Report, c'est-à-dire une étude dont les pairs vérifient la méthode avant de connaitre les résultats. Elle est du plus haut niveau de qualité possible.
Malheureusement, les chercheurs se sont frottés à un hic : les participants ne sont en réalité pas spécialement stressés avant leur partie. Ainsi, une intervention servant à réduire le stress ne va pas leur être très utile. Et c’est ce qui s’est passé, les résultats étant négatifs. Résultat en demi-teinte donc, mais ce qui est positif, cest que le format registered report leur a permis de quand même publier les résultats.
ChatGPT n’est pas détecté dans les tests universitaires
Des chercheurs ont fait une étude rigoureuse en aveugle dans laquelle ils ont soumis des copies faites à 100% par l’IA dans le système d'examination de cinq modules de licence. Ils l’ont fait pour toutes années d'études confondues, dans une licence de psychologie dans une université britannique réputée. 94 % des papiers soumis par l’IA n'ont pas été détectés. Les notes attribuées à ces copies étaient en moyenne légèrement supérieures à la moyenne obtenue par de vrais étudiants.
Dans tous les modules, il y avait 83,4 % de chance que les copies créées par l’IA sur un module surpassent une sélection aléatoire du même nombre de soumissions d'étudiants réels (et donc, que des étudiants qui utilisent complètement l’IA aient des notes légèrement meilleures que ceux qui ne l’utilisent pas).
Les raisons du dopage
Une méta-analyse de 25 études s’intéresse aux raisons qui font que les sportifs se dopent.
Les résultats ne sont pas très surprenants, mais voici la liste des facteurs de risques :
- Les intentions de se doper;
- Les normes incitant à se doper;
- L’utilisation de supplémentation;
- Les attitudes pro-dopage (voir que le dopage est quelque chose de positif);
- L’utilisation de substance non dopantes;
- L’exposition dans les médias mettant en avant l’apparence physique;
- Les comportements anti-sociaux;
- La non-satisfaction de son corps;
- Être en mauvaise santé;
- Faire des entrainements intensifs.
Pour les facteurs protecteurs, il y a le sentiment d’efficacité personnelle (se sentir efficace dans son entrainement) et une moralité positive : penser que le dopage est immoral.
La majorité des études sont faites sur un échantillon très faible et sont observationnelles, on est sûr du degré de preuve très faible.
Ntoumanis N, Dølven S, Barkoukis V, et al. Psychosocial predictors of doping intentions and use in sport and exercise: a systematic review and meta-analysis. British Journal of Sports Medicine 2024;58:1145-1156. https://doi.org/10.1136/bjsports-2023-107910
J’ai mal à ma ruche
Cette histoire a été racontée par Lior Patcher sur X (https://twitter.com/lpachter/status/1808263289987903964).
Aristote a été le premier à remarquer la danse des abeilles.
C’est en 1927 que Karl von Frisch a décodé le frétillement des abeilles, c'est-à-dire qu'il a compris comment le nombre de frétillements et leur direction communiquent des informations sur la distance et la direction des sources de nourriture. Von Frisch a remporté le prix Nobel pour sa découverte. Mais, son fonctionnement exact est resté un mystère.
Dans les années 1990, Un chercheur nommé Srinivasan a commencé à écrire des articles prétendant expliquer les mécanismes sous-jacents au frétillement. Ces papiers l'ont rendu célèbre. Il est devenu membre de la Royal Society et a remporté le Prix du Premier ministre (anglais) pour la science.
En 2020, Laura Luebbert, à l'époque jeune doctorante, a effectué un stage dans un laboratoire dans lequel elle devait lire deux articles de Srinivasan. Débutante sur le sujet, elle a lu quelques articles supplémentaires de Srinivasan pour les placer dans leur contexte. Elle a remarqué que les mêmes données apparaissaient encore et encore dans de nombreuses expériences différentes. Dans un billet de blog, elle a raconté l'histoire de la réaction qu'elle a reçue lorsqu'elle l'a signalé à son professeur (titulaire) de l'époque, et à d'autres chercheurs autour d’elle. En gros, on lui a dit de ne pas perdre son temps : « une grande partie de la littérature scientifique a des problèmes ». Elle a même tweeté sa découverte à l'époque parce quelle trouvait que c’était un gros problème. Comme toujours en science, on lui a fait une petite tape a l’épaule et on lui a dit “ça va aller, oublie tout ça”.
Elle a ignoré tous ceux qui lui disaient d’arrêter.
Lior, celui qui raconte l’histoire, a appris de Laura des années plus tard cette histoire, après qu'elle ait rejoint son laboratoire. Ils ont alors ensemble relu les articles scientifiques (une demi-douzaine) et ont remarqué de nombreux problèmes supplémentaires.
Ils ont décidé de rédiger ses observations. Par exemple, six articles ont rapporté un R² = 0,99 ce qui signifie que le modèle du chercheur était « parfait ». Pourtant les données collectées sont des expériences de suivi d'animaux vivants sur des caméras primitives au début des années 2000, avec des résultats très mauvais et peu précis. Même si les abeilles frétillaient parfaitement, on ne pourait pas avoir un résultat aussi proche de 1.
Laura a également constaté d'autres doublons et manipulations. Des trucs incroyables. Des données identiques ont été rapportées pour « différentes expériences » dans « différents articles ». C'est terriblement déprimant. Laura était douée pour fouiller dans ces saletés de recherche. Elle n'a pas seulement trouvé des doublons, mais aussi des erreurs dans les résultats principaux.
Ils ont ensuite soumis leur rapport à Bioarxiv preprint qui l'a rejeté. En effet, ils ne l'ont pas considéré comme de la « recherche », et leur article ne correspond pas à leur politique intérieure. Mais c'était frustrant. Surtout que leur réponse était que le manuscrit contenait « du contenu avec des attaques ad hominem » alors que ce n'est pas le cas.
Ils l’ont donc envoyé au Journal of Experimental Biology d'où provenaient certains des articles frauduleux. L’article a également rejeté en obligeant les chercheurs a contacter individuellement toutes les revues dont ils disaient qu’il y avait des problèmes dans les études. C'était encore plus frustrant.
Le tout est ici beaucoup plus grand que la somme des parties (Lior et Laura ne peuvent pas faire un commentaire pour chaque article dans chaque journal, ça serait trop long). Finalement, le Journal of Experimental Biology a publié des corrections pour deux des articles de Srinivasan que Laura avait signalés. Il y a répondu dans des commentaires. Dans l'un, Srinivasan *croit* que tout va bien. Dans un autre, il parle de son article contenant *probablement* les valeurs correctes. Et les articles n’ont pas été rétractés. Mais enfin, les éditeurs attribuent-ils maintenant une probabilité de véracité aux résultats ? Ils pratiquent une science basée sur la croyance ? Les corrections faites par le Journal of Experimental Biology ne sont clairement pas suffisantes
Finalement, le rapport a été déposé sur Arxiv, un serveur de préprint. Il a fallu 2 semaines pour que l’article soit accepté, enfin. Mais la science a un gros problème. Il devrait y avoir un endroit pour publier la critique d'un ensemble d’articles. Pas seulement une plainte à propos d'un article. C'est pourquoi les deux auteurs ont créé un article de blog « The Journal of Scientific Integrity » (https://liorpachter.wordpress.com/2024/07/02/the-journal-of-scientific-integrity/). Où se trouve ce journal ? Pourquoi est-il si tabou de faire face à l'inconduite d'un scientifique ? Les gens sont impatients de se jeter sur les femmes qui fraudent (par exemple, Claudine Gay), alors que des hommes devraient aussi rendre des comptes. Et dans ce cas, il s'agit d'une affaire très grave. Lior croit que la grande majorité des erreurs en science sont des erreurs innocentes. Mais quand ils semblent ne pas l'être, il devrait être acceptable de parler. Il devrait être acceptable de publier une critique sur un ensemble d’articles.
L’article : https://arxiv.org/pdf/2405.12998
L’image qui fait réfléchir
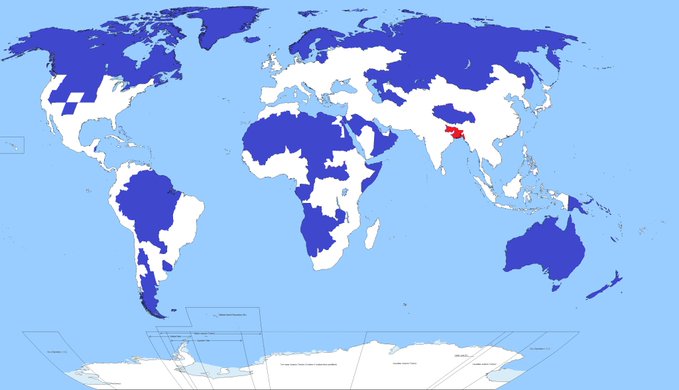
La population dans la zone en rouge est identique à la population dans les zones en bleu.
L’histoire problématique du trouble de la pensée formelle dans la schizophrénie
Aujourd’hui, on va discuter du chapitre 2 de la thèse du Dr Oli Delgaram-Nejad, chercheur anglais spécialisé dans la schizophrénie. Ainsi, si vous vous demandez si des gens lisent des thèses, la réponse est oui mais pas en entier.
Bon alors c’est quoi le trouble de la pensée formelle ? De manière très générale, on peut le définir comme une forme particulière de pensée. Elle ne fait pas partie des prérequis du diagnostic de schizophrénie mais y est très fortement associée.
Il existe une échelle mesurant ce trouble ; l’échelle de pensée, langage et communication (Andreasen, 1986) avec plein de bébés échelles qui se basent dessus.
Un premier souci est que ni Andreasen, ni les autrices et auteurs qui ont créé les échelles suivantes, ne sont des linguistes. Il n’y a donc jamais eu d’examen linguistique d’un trouble du langage. De plus, ces échelles se basent essentiellement sur des observations cliniques, et les évaluations psychométriques basés sur les qualités internes du test, et pas sa validité linguistique.
C’est ce point qui est développé dans la thèse.
...
Psycho Papers
Psycho Papers