Psycho Papers #47 : la newsletter où on dit constamment des trucs.
De vraies informations bien vérifiables - FDA, maladies chroniques et remboursement - ChatGPT 4.0 est toujours complètement pété - Le dentifrice est-il nécessaire ? - les chercheurs faisant des études en ligne sont désespérants de jemenfoutisme - Pour les abonnés, une étude sur l'ocytocine intranasale


Qu’est-ce qui amène à croire une information ?
Une étude a manipulé la source de l’information, la répétition de l’information et la présentation de l’information. Elle a testé ces trois facteurs dans 4 études différentes sur plus de 300 participants.
Les auteurs ont testé 36 faux scénarios. Un exemple sur la source : “ Hillary Clinton a révélé dans une interview qu'elle voulait devenir astronaute dans le passé et a demandé à la NASA dans une lettre ce qu'il fallait faire pour y parvenir. La réponse : « Soyez un homme !” et la source était soit CNN, soit KKN. Pour la répétition, les chercheurs ont mis plusieurs fois le même scénario dans l’expérimentation et pour la présentation de l’information, ils ont ajouté des Logos ou des images. Dans l’exemple précédent, l’image est:

L’étude a trouvé que des trois facteurs, la répétition de l’information est la manière la plus efficace de convaincre de la vérité de l’information, suivie de la source, tandis que la présentation (avec ou sans image) n’avait pas tellement d’influence.
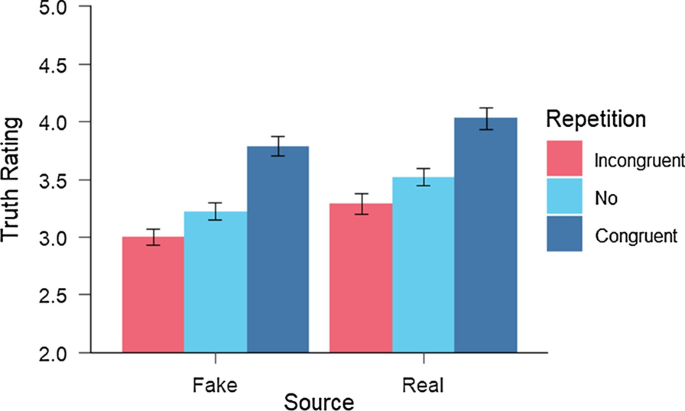
On comprend alors pourquoi certains peuvent mentir de manière répétée dans les médias : ils deviennent crédibles simplement en répétant à l’identique leur mensonge. Redoutable.
Nadarevic, L., Reber, R., Helmecke, A.J. et al. Perceived truth of statements and simulated social media postings: an experimental investigation of source credibility, repeated exposure, and presentation format. Cogn. Research 5, 56 (2020). https://doi.org/10.1186/s41235-020-00251-4
L’administration en charge des médicaments américains ne se base pas sur les preuves scientifiques
La FDA – Food and Drug Administration est l’organisme américain gérant la mise en circulation des médicaments. Une étude publiée dans JAMA indique que la majorité des critères de substitution (une mesure d’efficacité d’un traitement spécifique) utilisés dans les essais cliniques pour soutenir l'approbation par la FDA de médicaments indiqués dans des maladies chroniques (hors oncologie) manquent de données probantes et ne se basent pas sur des méta-analyses.
Plus exactement, 59% des critères portant sur 21 maladies différentes ne se basaient pas sur des méta-analyses. Pour les 41% autres, il n’y avait généralement qu’une seule méta-analyse disponible, ce qui amène à manquer de preuve fiable de lien avec des améliorations cliniques des médicaments.
Ces résultats soulignent l'importance de rendre public un résumé des preuves à l'appui des critères amenant à l'approbation par la FDA des médicaments traitant les maladies chroniques. Sans cela, les promoteurs de médicaments ne vont pas choisir des critères de substitution appropriés pour les essais et guider les médecins et leurs patients à mieux interpréter les avantages cliniques des médicaments approuvés dans le traitement des troubles chroniques.
Wallach, J. D., Yoon, S., Doernberg, H., Glick, L. R., Ciani, O., Taylor, R. S., Mooghali, M., Ramachandran, R., & Ross, J. S. (2024). Associations Between Surrogate Markers and Clinical Outcomes for Nononcologic Chronic Disease Treatments. In JAMA (Vol. 331, Issue 19, p. 1646). American Medical Association (AMA). https://doi.org/10.1001/jama.2024.4175
ChatGPT 4.0 est toujours complètement pété
Une équipe de chercheurs a mis au point un test d'association implicite de larges modèles de langage pour détecter les biais implicites. Ils ont constaté que sur 20 stéréotypes, ChatGPT 4.0 est fortement biaisé, même s'il est un peu moins que chatGPT 3.5.
Voici un exemple montrant que les 8 mots positifs sont pour le terme Blanc, tandis que les 8 mots négatifs sont pour le terme Noir.

Au-delà du fait que ChatGPT est fondamentalement racisme (ni plus ni moins que le corpus de données sur lequel il se base), les auteurs indiquent que ce type de test de mesure implicite (dans lequel on mesure des couleurs sans indiquer qu’elles se fondent sur des typologies humaines) est approprié pour tester les biais de stéréotypes dans les modèles de langage.
Bai, X., Wang, A., Sucholutsky, I., & Griffiths, T. L. (2024). Measuring Implicit Bias in Explicitly Unbiased Large Language Models (Version 2). arXiv. https://doi.org/10.48550/ARXIV.2402.04105
Le dentifrice est-il nécessaire ?
Il est indéniable que le brossage de dent évite les caries et infections buccales. Il est indéniable que le fluor protège également des caries. Mais est-il nécessaire de brosser les dents avec du dentifrice ? La réponse est, on ne sait pas.
Selon Ross Pomeroy, il est tout à fait possible d’imaginer que se brosser les dents « à sec » et se rincer la bouche avec une solution au fluor serait aussi efficace que se brosser les dents avec du dentifrice : "Les principales variables seraient si le rince-bouche au fluor avait la même concentration et la même durée de contact avec les dents que le dentifrice, si les dents étaient propres lorsque le rince-bouche a été utilisé, etc. Si ceux-ci sont maintenus constants, ce serait la même chose.”
Aux USA, pays dans lequel une vague de fausses informations circulent au sujet du fluor, il est nécessaire de rappeler que le fluor est obligatoire pour combattre les caries et que si le prix du dentifrice est trop élevé, plutôt que de le remplacer par une solution de rinçage, il est préférable d’en mettre moins sur sa brosse à dent. Une dose semblable à un petit pois suffit largement.
https://bigthink.com/health/do-you-need-toothpaste/
Désespérant de jemenfoutisme
Un groupe de chercheurs s’est intéressé à la rigueur des questionnaires en ligne dans les études de psychologie publiées dans des revues scientifiques. Ils ont utilisé les données de 3,298 articles publiés en 2022 provenant de 200 journaux différents.
Ils ont regardé à quel point les chercheurs ont mis en place des vérifications pour améliorer la qualité des réponses à ces questionnaires en ligne, que cela soit en bloquant les robots qui remplissent automatiquement les réponses, en faisant des vérifications d’attention ou de compréhension, ou en regardant les résultats finaux pour vérifier qu’il n’y en avait pas de « bizarre ».
Le résultat laisse sans voix :
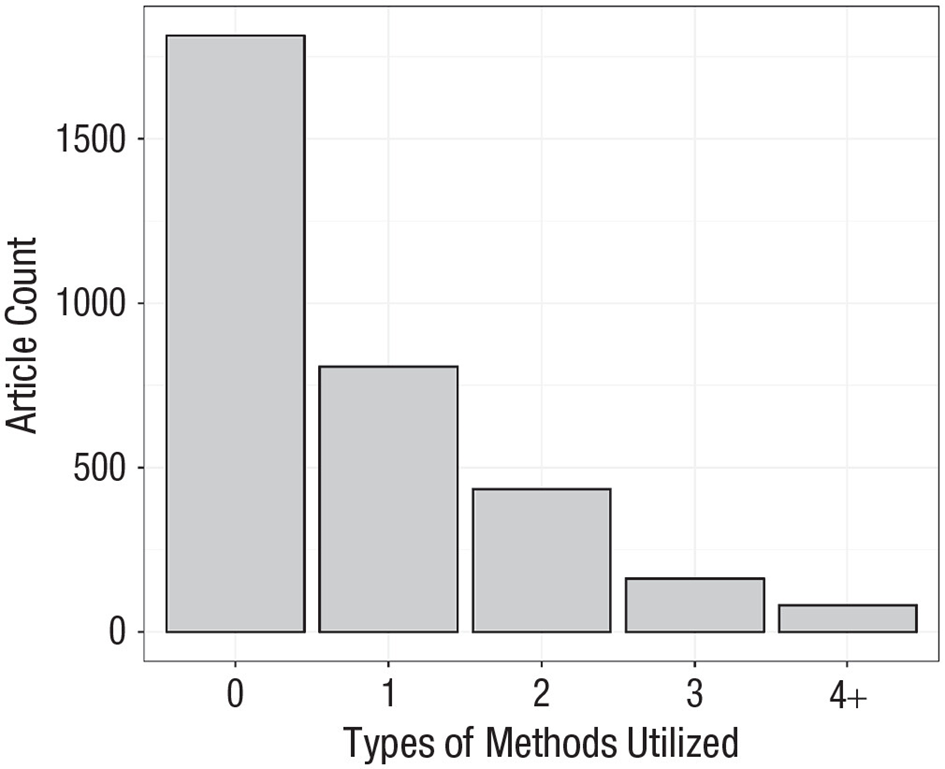
55% des articles se basent sur des données qui n’ont aucune méthode permettant de s’assurer de leur qualité (0, à gauche). Dans le reste, beaucoup de chercheurs indiquent avoir « supprimé des participants à cause de données manquantes » sans justifier la raison pour laquelle il faudrait supprimer les données complètes des participants.
Sur un point plus positif, vu qu’il faut en trouver, 20 % des articles utilisaient des « items contrôles », vérification d’attention ou de compréhension, ce qui est mieux que rien.
Rappelons aux (rares) chercheurs qui nous lisent qu’il est obligatoire de faire 1) un filtre avant récolte des données, 2) ajouter des questions d’attention et de vérification à chaque page, 3) des questions de compréhension à la fin du questionnaire (comme par exemple, “savez-vous parler anglais ?”), 4) une analyse des temps de réponse des participants et 5) une analyse fine de la distribution des données par question une fois la passation réalisée.
Pour la seule vérification des temps de réponse des participants, ce qui est le minimum du minimum, moins de 10 % des études rapportent l’avoir fait.
Gottfried J. Practices in Data-Quality Evaluation: A Large-Scale Review of Online Survey Studies Published in 2022. Advances in Methods and Practices in Psychological Science. 2024;7(2). doi:10.1177/25152459241236414
L’image qui fait réfléchir
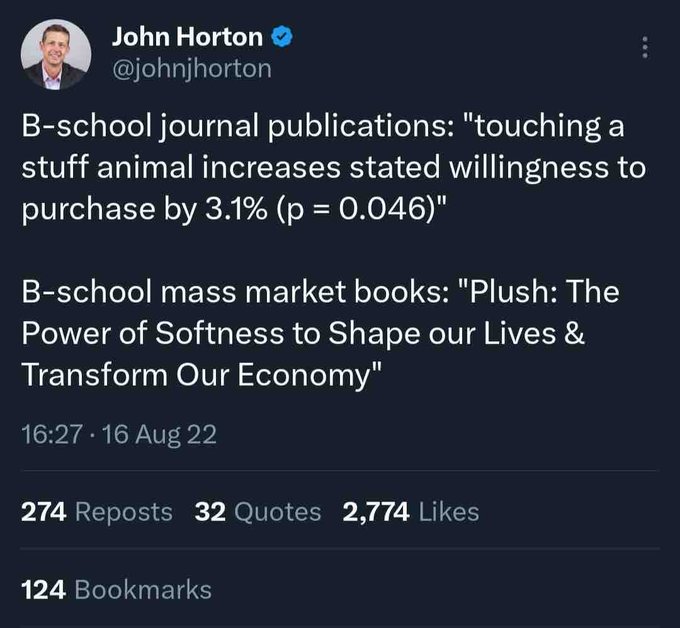
Le livre publié par l’école de commerce “La peluche : le pouvoir de la douceur pour former nos vies et transformer notre économie”
A noter que le p=0.046 implique que le résultat est tout juste significatif, indicateur de pratique de recherche questionnable voir de fraude, fortement prévalente dans les études en marketing.
Veille en psychologie clinique
Aujourd’hui, on exerce un œil critique sur un article publié sur l’ocytocine.
En effet, il va falloir parler d’un domaine qui me hérisse le poil : les études qui font tout pour trouver des résultats significatifs. Attention, je n’insinue pas que les chercheurs de cette étude ont volontairement falsifié leurs données (je ne veux pas risquer une nouvelle menace de procès) mais que cette étude utilise une méthodologie permettant de toujours trouver des résultats significatifs même si la théorie est fausse.
Mais commençons par le commencement. Pourquoi utiliser de l’ocytocine intranasal ? En 1988, une étude a montré que l’utilisation d’ocytocine intranasal module l’expression de comportements sociocognitifs. Cet effet a ensuite été répliqué des centaines de fois jusqu’à aujourd’hui ce qui a amené des chercheurs à supposer que l’ocytocine intranasal puisse « guérir » des troubles psychiatriques, des troubles caractérisés par des dysrégulations sociales et/ou émotionnelles, tels que l'autisme, le trouble de la personnalité limite, le trouble de stress post-traumatique et la schizophrénie, et ce, soit grâce à une utilisation unique, soit une utilisation chronique. Bref, ça soigne tout, peu importe comment c’est administré.
...
Psycho Papers
Psycho Papers